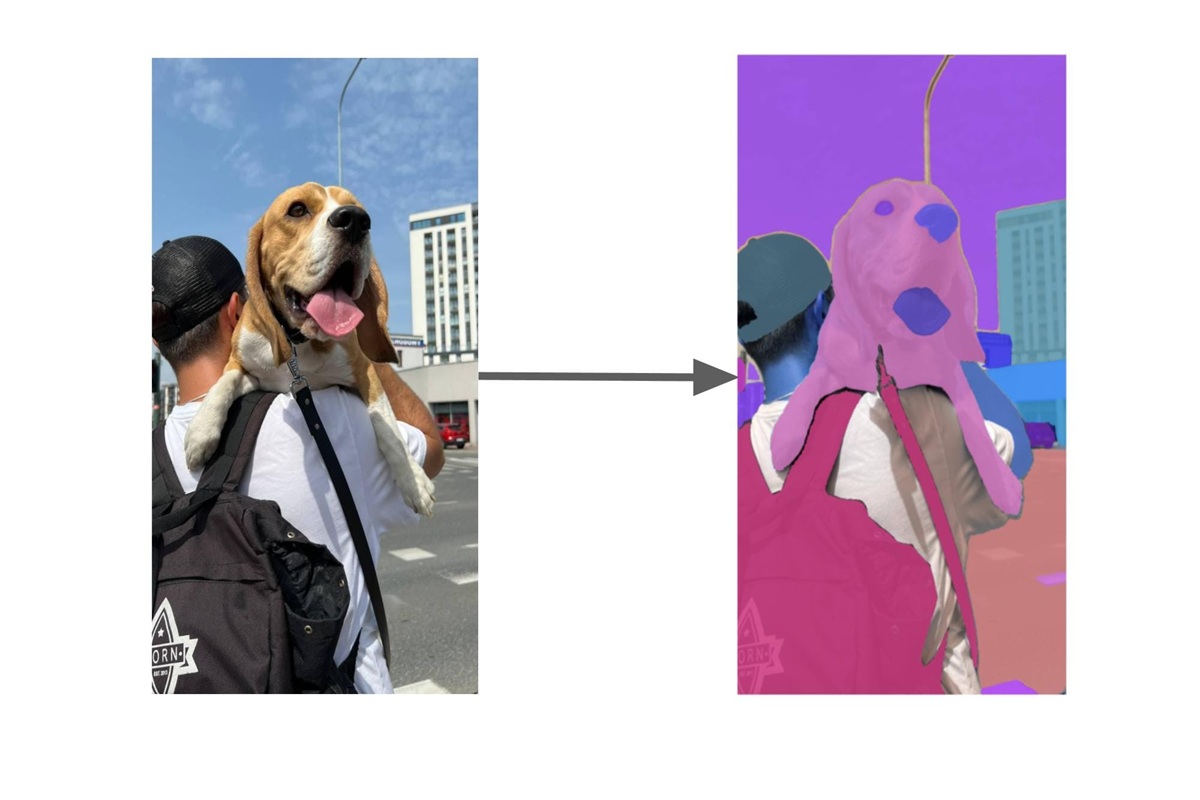
مدل Segment Anything 2 (SAM 2) که توسط Meta AI توسعه یافته است، نسخه پیشرفتهای از مدل Segment Anything (SAM) است که قابلیتهای جدیدی در زمینه تقسیمبندی تصاویر و ویدئوها ارائه میدهد. این مدل بهویژه در کاربردهای پزشکی، ویدئو، و تعاملات مبتنی بر ورودیهای مختلف مانند کلیک، جعبه یا ماسک، توانمندیهای قابلتوجهی از خود نشان داده است.
🔍 ویژگیهای کلیدی SAM 2
معماری ترنسفورمری ساده با حافظه جریانی:
این طراحی امکان پردازش ویدئویی در زمان واقعی را فراهم میکند.
دادهموتور تعاملی:
با جمعآوری بزرگترین مجموعه داده تقسیمبندی ویدئویی از طریق تعاملات کاربر، مدل و دادهها بهطور همزمان بهبود مییابند.
پشتیبانی از ورودیهای متنوع:
امکان استفاده از کلیک، جعبه یا ماسک بهعنوان ورودی برای انتخاب یک شیء در هر تصویر یا ویدئو.
عملکرد برتر در تقسیمبندی ویدئویی:
در مقایسه با روشهای قبلی، SAM 2 دقت بالاتری را با استفاده از ۳ برابر تعاملات کمتر ارائه میدهد.
عملکرد سریعتر در تقسیمبندی تصویر:
این مدل ۶ برابر سریعتر از نسخه قبلی خود در تقسیمبندی تصاویر عمل میکند.
🧪 کاربردهای پزشکی
مطالعات نشان دادهاند که SAM 2 در تقسیمبندی ارگانهای شکمی در تصاویر سیتیاسکن عملکرد قابلتوجهی دارد، بهویژه برای ارگانهای بزرگتر با مرزهای واضح. این مدل در شرایطی با کیفیت تصویر پایین مانند دود، خونریزی یا نور کم نیز عملکرد مناسبی از خود نشان داده است.
📥 دسترسی و استفاده
برای استفاده از SAM 2، میتوانید از نسخههای آنلاین و تعاملی ارائهشده توسط Meta یا GitHub استفاده کنید. همچنین، Meta کدهای آموزشی و مدلهای پیشآموزشدیده را در دسترس عموم قرار داده است.
📄 مقاله اصلی
برای مطالعه کامل مقاله SAM 2، میتوانید به لینک زیر مراجعه کنید:
🔗 SAM 2: Segment Anything in Images and Videos
🧠 مدل Segment Anything 2 (SAM 2)
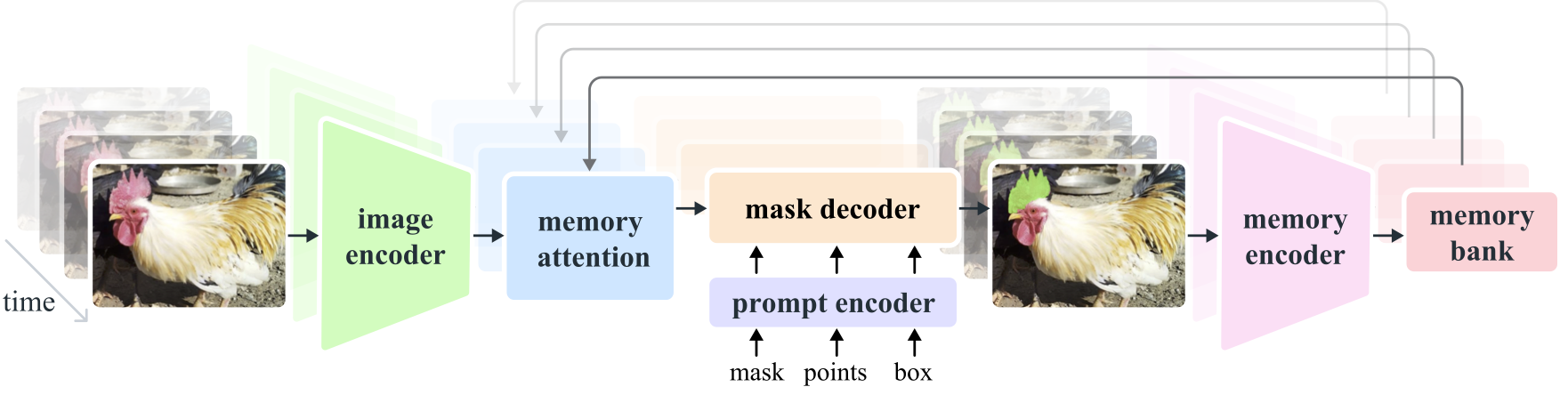
مدل SAM 2 یک مدل پایهای است که برای حل وظیفه تقسیمبندی بصری قابل درخواست در تصاویر و ویدئوها طراحی شده است. این مدل از یک معماری ترنسفورمر ساده با حافظه جریانی برای پردازش ویدئویی در زمان واقعی استفاده میکند. با استفاده از تعاملات کاربر، یک موتور داده ساخته شده است که مدل و دادهها را بهبود میبخشد و بزرگترین مجموعه داده تقسیمبندی ویدئویی را تا به امروز جمعآوری میکند. مدل SAM 2 آموزشدیده بر روی این دادهها عملکرد قویای در طیف وسیعی از وظایف ارائه میدهد.
🎯 وظیفه تقسیمبندی بصری قابل درخواست (PVS)
وظیفه PVS، تقسیمبندی تصویر را به دامنه ویدئو تعمیم میدهد. این وظیفه ورودیهایی مانند نقاط، جعبهها یا ماسکها را در هر فریم ویدئو میگیرد تا یک بخش از علاقه را تعریف کند که ماسک فضایی-زمانی آن پیشبینی شود. پس از پیشبینی یک ماسک، میتوان آن را با ارائه ورودیهایی در فریمهای اضافی بهطور مکرر اصلاح کرد.arXiv
🧪 معماری مدل
مدل SAM 2 از یک معماری ترنسفورمر با حافظه جریانی استفاده میکند که به آن امکان میدهد اطلاعات مربوط به شیء و تعاملات قبلی را ذخیره کرده و پیشبینیهای ماسک را در طول ویدئو تولید کند. این معماری بهطور طبیعی تعمیمی از SAM به دامنه ویدئو است که فریمهای ویدئویی را یکییکی پردازش میکند و از یک ماژول توجه حافظه برای توجه به حافظههای قبلی شیء هدف استفاده میکند.
📊 مجموعه داده SA-V
برای آموزش مدل، یک موتور داده ساخته شده است که با استفاده از مدل در حلقه با حاشیهنویسان، دادههای جدید و چالشبرانگیز را بهطور تعاملی حاشیهنویسی میکند. این موتور داده با SAM 2 در حلقه، ۸.۴ برابر سریعتر از روشهای موجود با کیفیت مشابه است. مجموعه داده نهایی Segment Anything Video (SA-V) شامل ۳۵.۵ میلیون ماسک در ۵۰.۹ هزار ویدئو است که ۵۳ برابر بیشتر از هر مجموعه داده تقسیمبندی ویدئویی موجود است.arXiv+2GitHub+2
📈 ارزیابی و نتایج
آزمایشها نشان میدهند که SAM 2 تجربه تقسیمبندی ویدئویی را بهطور قابلتوجهی بهبود میبخشد. SAM 2 میتواند دقت تقسیمبندی بهتری را در حالی که از ۳ تعامل کمتر از روشهای قبلی استفاده میکند، ارائه دهد. علاوه بر این، SAM 2 در مقایسه با مدل SAM در بنچمارکهای تقسیمبندی تصویر، دقت بالاتری دارد و ۶ برابر سریعتر است.
🛠️ کاربردهای عملی SAM 2
ویرایش ویدئو: این مدل میتواند به راحتی اشیاء خاصی را در ویدئوها شناسایی کرده و آنها را برای ویرایشهای بعدی انتخاب کند.
خودروهای خودران: در سیستمهای رانندگی خودکار، SAM 2 میتواند به شناسایی و دنبال کردن عابران پیاده، خودروها و ویژگیهای جاده کمک کند.
تصویربرداری پزشکی: در تحلیل ویدئوهای پزشکی مانند آندوسکوپی، این مدل میتواند به پزشکان در شناسایی و بررسی دقیقتر نواحی مختلف کمک کند.
واقعیت افزوده: در برنامههای واقعیت افزوده، SAM 2 میتواند به شناسایی و تعامل با اشیاء موجود در نمای دوربین دستگاه کمک کند.